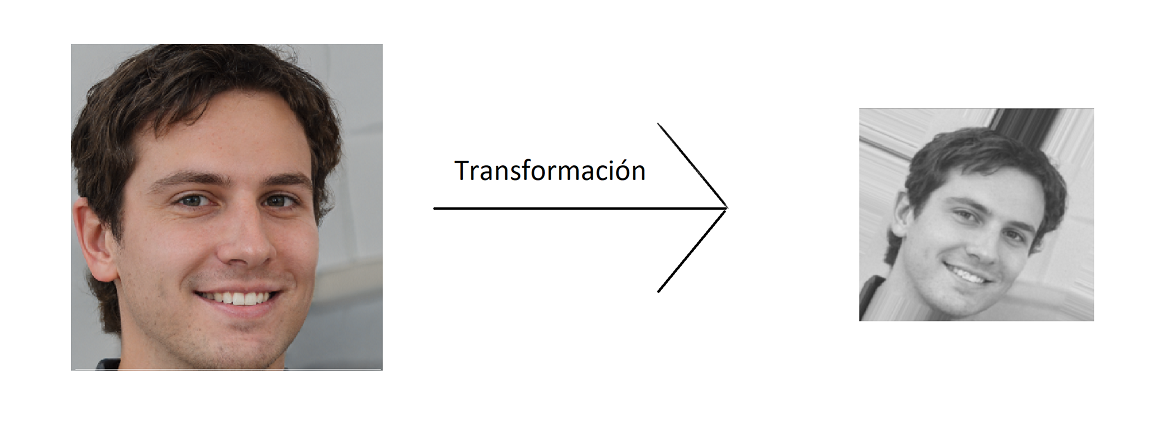
Resulta interesante y además de suma utilidad identificar características particulares
en diferentes imágenes
que se
tengan a disposición. Sin embargo, esta tarea puede resultar altamente exhaustiva si se realiza a manos
humanas. Así
entonces, en este desarrollo se aborda el asunto de identificación de características particulares en fotos
y con
ello la clasificación de las mismas, pero haciendo uso de múltiples técnicas estadísticas para la
automatización del
proceso.
Específicamente se desea clasificar imágenes de personas, las cuales serán
categorizadas según si hacen uso o
no de
lentes de sol. Para esta causa, se debe proceder inicialmente con la construcción de una base de datos de un
buen
tamaño que permita la implementación de algún modelo apropiado para la tarea de clasificación. Continúa
leyendo para
adentrarte en los detalles de este proyecto.
Web Scraping y construcción
de la base de datos
Como se mencionó anteriormente, en un primer paso se debe proceder a construir una
base de datos
(suficientemente
grande) para entrenar un modelo de clasificación que pueda identificar con un buen desempeño si una persona
usa o no
gafas de sol. Sin embargo, recopilar una cantidad de imágenes suficiente puede no ser muy práctico en
términos de
tiempo.
Por esto, se decidió automatizar este proceso haciendo uso de Scrapy como backend para
obtener imágenes a
través de
Splash.
En un primer intento la página de Freepik sirvió
como sitio contenedor
de las
imágenes, sin embargo, esta metodología resultó poco factible ya que se dificulta el control de las imágenes
obtenidas a través de esta técnica de programación.
Luego de esto se recopiló una base de datos encontrada en la plataforma Kaggle para
posteriormente preprocesarla y ajustar diversos modelos con esta.
Preprocesamiento de la base de datos
Una vez obtenidas las imágenes con las cuales se va a entrenar el modelo de
clasificación, gracias al método
por el
cuál fueron obtenidas, pudieran filtrarse algunas cuantas que no cumplan con los requisitos deseados para un
correcto entrenamiento del modelo de clasificación. Además de esto, no todas las fotos se encuentran en la
misma
escala de pixeles, por lo cuál se debe depurar la base de datos y redimensionar las imágenes a un tamaño
estándar de
alto y ancho.
Teniendo en cuenta que la base de datos recolectada a través de web scrapping no era de muy buena calidad,
se decidió tomar una base de datos distinta, la cual se preprocesó y modificó usando el paquete Keras. Allí
se escalaron las imágenes a un tamaño 30x30 puesto que las imágenes objetivo (las del CMU) se encontraban en
relación de aspecto 32:30, así, esta elección era adecuada para no perder mucha calidad en las imágenes,
teniendo en cuenta tanto la relación de aspecto de las imágenes del CMU como el hecho de que todas las
imágenes de la nueva base de datos son cuadradas. Adicionalmente, se generaron más imágenes introduciendo
ruido en estas, como se puede ver a continuación.
Depuración
Como se mencionó en el apartado anterior, se cuenta con dos carpetas, una que contiene
las imágenes de
personas que
usan gafas de sol y otra en donde las imágenes son de personas sin estas. Así entonces, para depurar las
imágenes
que no cumplieran con alguno de estos dos requisitos respectivos, se realizó manualmente la tarea de revisar
de
forma exhaustiva cada una de estas dos carpetas, eliminar los elementos no deseados y de este modo conseguir
un
material de trabajo limpio y apropiado para los desarrollos posteriores.
Adecuación de la escala y color
Para estandarizar el tamaño de las imágenes se usó la librería de python OpenCV,
específicamente el método
"resize" con la cual se definió un tamaño de 32x30 pixeles para cada imágen en la base de datos.
En un primer intento se intentó acudir a la librería Skimage con su método propio
"resize", para
realizar
esta tarea, sin embargo, al intentar guardar la imágen el archivo se corrompía y se conseguía por resultado
un
fondo
negro sin ningún tipo de información relevante.
Por último, para terminar con la adecuación pertinente del material, se transformaron
las imágenes de formato
RGB a
escala de grises con el fin de obtener un solo canal, el cual corresponde a la intensidad, y simplificar de
este
modo los procesos posteriores.
Es necesario hacer mención que para la base de datos nueva se realizó toda la adecuación usando netamente
Opencv y Keras.
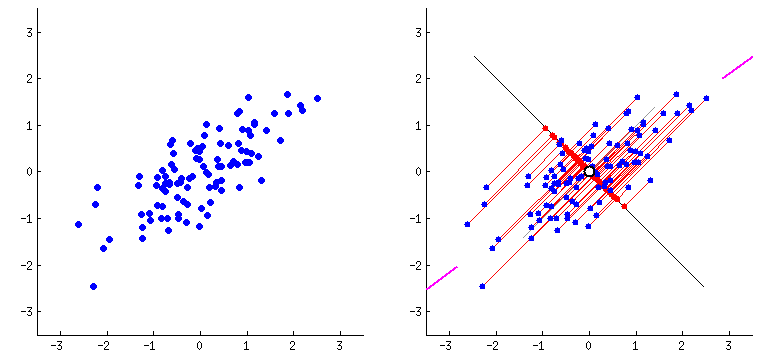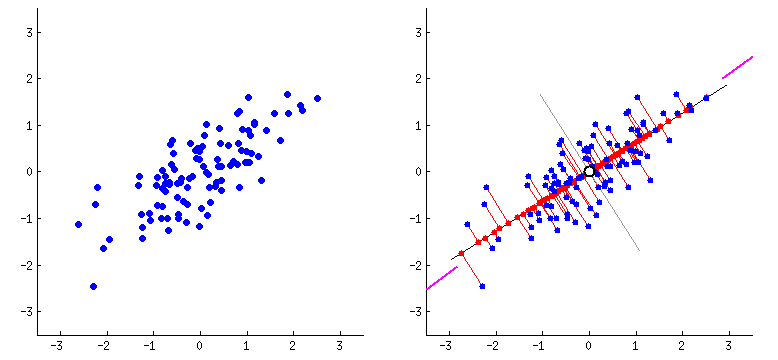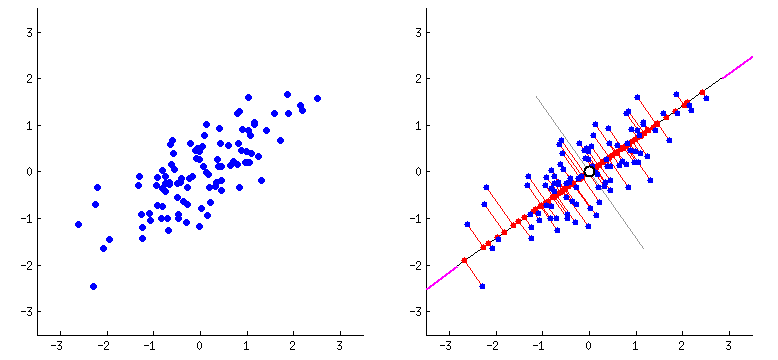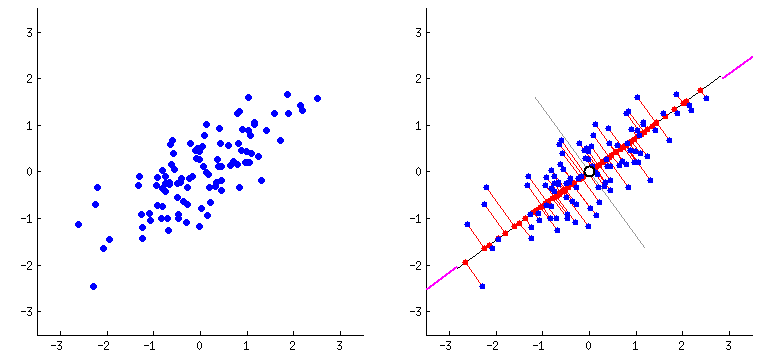
Componentes principales
Con lo anterior se logró construir una base de datos extensa que comprendió 32 x 30 =
960 variables
constituídas por
la intensidad de pixeles en cada imágen. En total se obtuvieron 6313 observaciones (imágenes) en 960
variables.
Una vez con el material adecuado a disposición, el proceso a seguir en este desarrollo
fue apostar a una
reducción de
la dimensionalidad original de los datos usando la metodología de análisis de componentes principales (PCA).
Sabiendo de antemano la teoría necesaria para llevar a cabo este método de aprendizaje
no supervisado, se
acudió a la
clase PCA de la librería sklearn.decomposition, con la cual se construyó un wrapper que cumplió la función
de
aplicar esta metodología a los datos originales conservando únicamente las componentes principales que
lograran
explicar un porcentaje de variabilidad deseado por el usuario, en este caso del 90%.
Finalmente, implementado el procedimiento anterior, se obtuvo un reducción de
dimensionalidad sustancial
conservando
únicamente 155 componentes principales, es decir, un 16.14% de la información total para explicar
mínimamente el 90%
de la variabilidad total.
Con esto, se llegó a una base de datos ideal para comenzar el proceso de modelación.
Modelado
Haciendo una rápida investigación en diversos portales de internet, se notó que para
problemas de
clasificación de
imágenes, es de suma popularidad la implementación de redes neuronales para esta tarea, siendo estas las más
usadas
en competencias de kaggle y las de más renombre en artículos de Machine Learning orientados a la
clasificación de
imágenes por características puntuales.
Implementación y resultados
Inicialmente, se ajustaron varios modelos como bosques aleatorios y redes neuronales
artificiales haciendo
uso de las
componentes principales descritas en el apartado anterior. Sin embargo, estos esfuerzos resultaron
infructuosos
puesto que los modelos obtuvieron desempeños muy pobres y presentaron un marcado sobreajuste. Esto puede ser
explicado gracias a la naturaleza del primer método de clasificación y debido a no tomar medidas preventivas
como el
dropout en el segundo. Cabe resaltar también, que la base de datos contruída a través de web Scraping no era
la más
adecuada y con esto se puede explicar en cierta medida el por qué del pobre poder predictivo de los modelos
obtenidos en un primer acercamiento a la resolución.
Luego de esto, como se mencionó anteriormente, se opta por usar una base de datos de
la plataforma Kaggle, la cual contiene
sujetos
tanto con
lentes como sin lentes. El modelamiento en este paso se hizo a través del API de Keras, el cual permitió el
preprocesamiento de las imágenes y el ajuste de una red neuronal convolucional, posibilitando generar más
imágenes
de las que se disponía introduciendo ruido y variaciones en estas, como por ejemplo reflejarlas
verticalmente,
rotarlas o cambiar su tamaño.
Funcionamiento del modelo
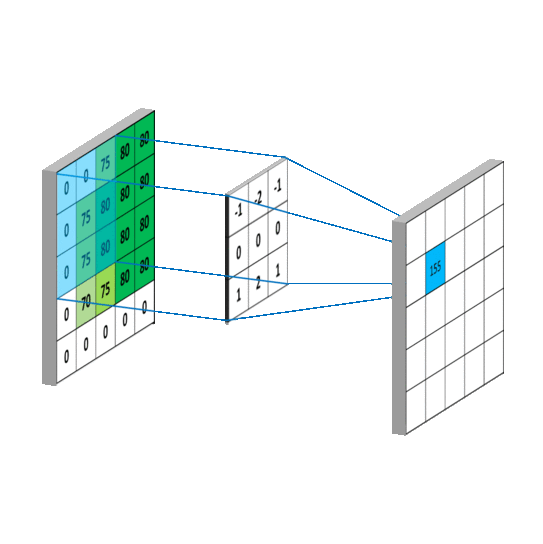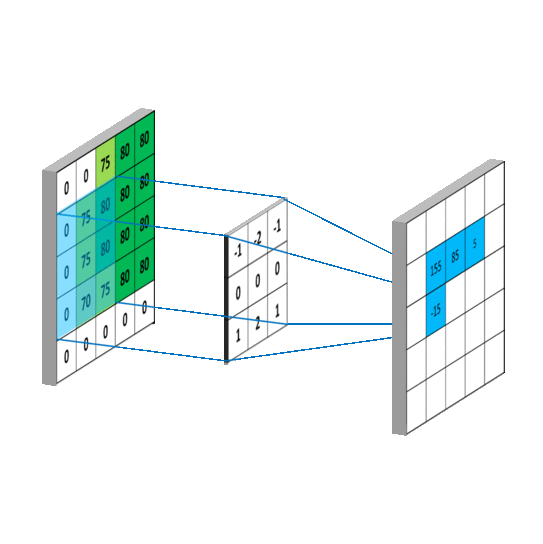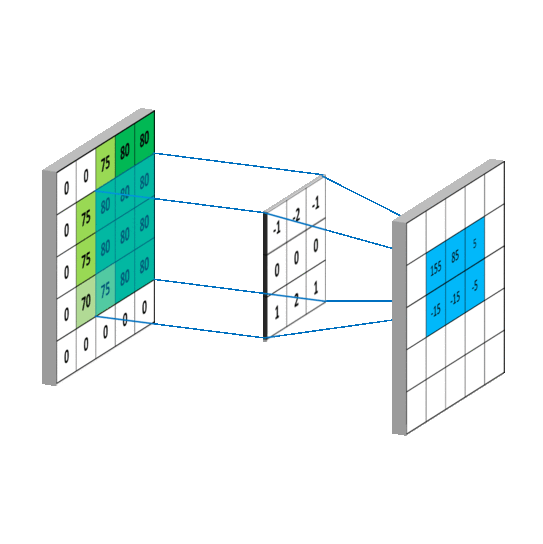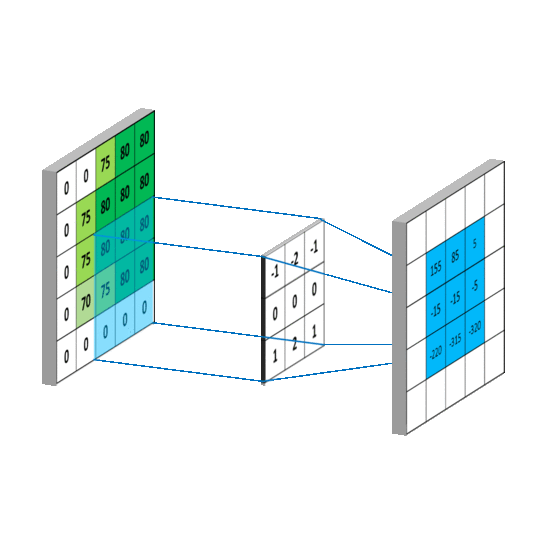
En primer lugar el modelo realiza un preprocesamiento de la imagen como se muestra a continuación
Luego de esto, se realiza una convolución en las imágenes para luego así ir extrayendo carácteristicas
importantes de las imágenes usando un agrupamiento de
pixeles 2x2
Finalmente, las imagenes resultantes son aplanadas y son pasadas por dos capas de una red neuronal
artificial,
la cual intenta predecir si el individuo tiene gafas (0) y si el individuo no tiene gafas (1).
Reporte de métricas
A continuación se presetan algunas métricas obtenidas por el modelo tanto en el
conjunto de entrenamiento
como en el de validación.
Conjunto de datos
Exactitud
Precisión
Especificidad
Entrenamiento
0.55044
0.3554
0.2835
Validación
0.4322
0.3571
0.9253
Conclusiones
En el conjunto de validación el modelo se ve fuertemente afectado por el
tamaño de las imágenes
puesto que, este fué entrenado usando fotos en formato cuadrado, por lo cual a la hora de realizar
las respectivas predicciones, fué necesario redimensionar las imágenes del conjunto de validación,
perdiendo de este modo mucha calidad y afectando drásticamente el desempeño del modelo final.
Para mejorar la capacidad de respuesta del modelo entrenado, las imágenes con
las cuales se entrene y
se ponga a prueba deben ser concretas en su contenido, es decir, que el enfoque principal de la
fotografía se dirija hacia la cara del sujeto y si este mismo posee o no lentes, evitando de este
modo ambiguedades, ruido en el modelo y por ende un pésimo desempeño.
Por último, se recomienda a las personas interesadas en esta línea de trabajo,
que se enfoquen en
recopilar material de entrenamiento claro y de gran calidad en haras de ajustar modelos robustos y
de buen desempeño que generalicen según lo esperado.
Repositorio de GitLab
Si quieres ver el código con el que fue hecho este modelo
y todo lo que hay detrás de el como la construcción de los datos,
el ajuste, entre otros, te invitamos
a que visites el repositorio del proyecto. Da click al logo para más información.